 浅谈MVC分层及层对象传递实践
浅谈MVC分层及层对象传递实践
# 前言
作为一名初学者,我常常在想到底怎么样的代码 “规范”,为什么「阿里巴巴 Java 开发手册」里有这么多种领域对象,经过翻阅资料、请教 leader,浅薄的得出以下观点,随着了解的深入本文会不断完善。
# MVC
MVC
MVC 模式(Model–view–controller)是软件工程 (opens new window)中的一种软件架构 (opens new window)模式,把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
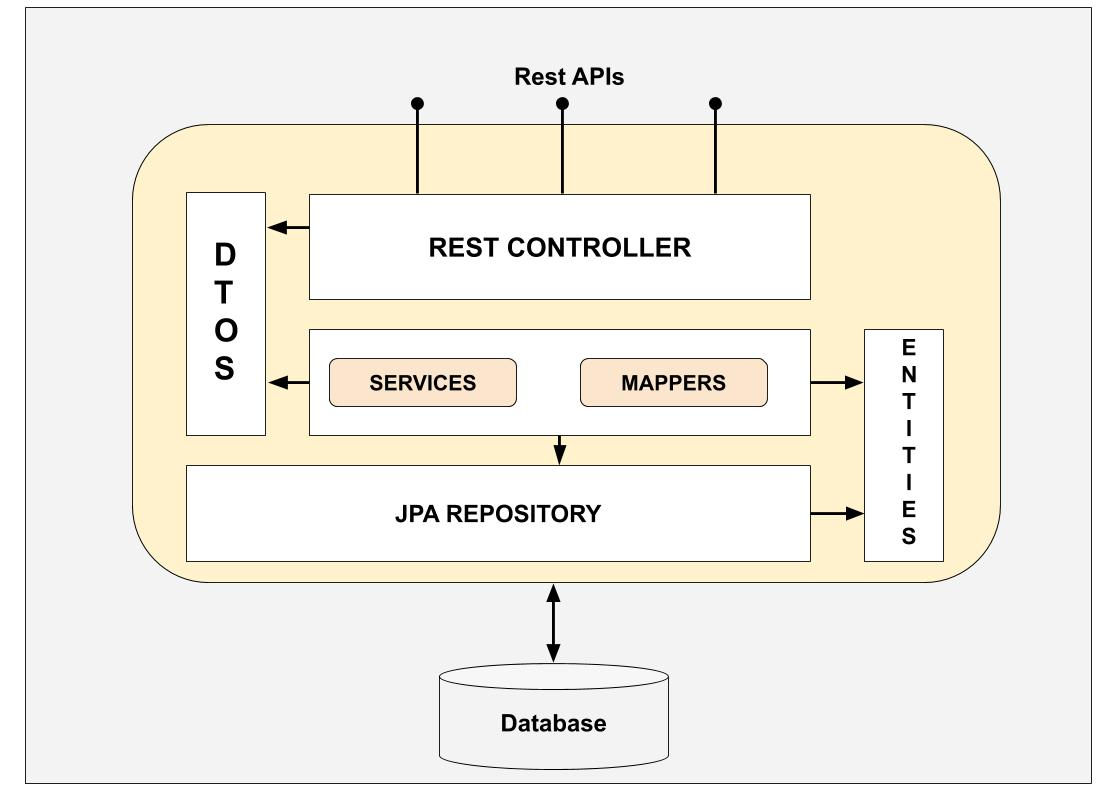
在传统的 MVC 模式中,系统分为三层,而前后端分离的当下,使用 Spring MVC 开发时实际上可分为五层(甚至更多):
- UI 层(浏览器)
- 控制器层
@Controller - 服务层
@Service - 通用业务处理层
@Repository - 数据访问层
@Mapper
每一层的作用以及层与层之间的数据该如何交互是本文将要讨论的重点
# UI 层
UI 层最靠近用户,用于显示数据和接收用户输入的数据,为用户提供一种交互式操作的界面。在前后端分离下,UI 层开发不再是后端工程师的职责,这里不展开讨论。“UI 层” 也只是一个笼统的叫法,前端工程师还会将 UI 层再细分为 M-V-VM 模式。
# 控制器层 Controller
主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
private final StudentService studentService;
@GetMapping()
public Result<List<StudentResp>> list(StudentQuery query) {
return Result.ofSuccess(studentService.list(query));
}
@GetMapping("/{id}")
public Result<StudentResp> detail(@PathVariable Long id) {
return Result.ofSuccess(studentService.detail(id));
}
@PostMapping()
public Result<Void> create(@RequestBody @Validated StudentReq req) {
studentService.save(req);
return Result.ofSuccessMsg("新增成功");
}
@PutMapping()
public Result<Void> update(@RequestBody @Validated StudentReq req) {
studentService.updateById(req);
return Result.ofSuccessMsg("更新成功");
}
@DeleteMapping("/{id}")
public Result<Void> delete(@PathVariable Long id) {
studentService.deleteById(id);
return Result.ofSuccessMsg("删除成功");
}
入参校验
在前后端分离下,controller 层是后端最接近用户(前端)的层,在接收用户参数时应使用 @Validated 配合相关注解,校验入参对象属性的非空、非 Null 等基础参数校验,而一些业务上的联动校验等复杂校验则在对应 Service 层作为业务逻辑的一部分处理。
调用服务层实现功能
控制器层一般不作业务处理,而是调用服务层对应方法来处理,控制器的角色是一位调度者,它负责将数据传递到对应服务层方法,等待返回结果。
结果封装
待服务层方法返回结果或未出现异常时,应将结果或操作成功(未发生异常视为成功)封装成前后端约定格式返回给前端。
# 服务层 Service
相对具体的业务逻辑服务层。
private final StudentManager studentManager;
public List<StudentResp> list(StudentQuery query) {
List<Student> list = studentRepository.listBy(query);
return BeanUtil.copyToList(list, StudentResp.class);
}
public StudentResp detail(Long id) {
Student student = studentManager.getById(id);
return BeanUtil.copyProperties(student, StudentResp.class);
}
public void save(StudentReq req) {
Student student = BeanUtil.copyProperties(req, Student.class);
Assert.isTrue(studentManager.save(student), "新增失败");
}
public void updateById(StudentReq req) {
Student student = BeanUtil.copyProperties(req, Student.class);
Assert.isTrue(studentManager.updateById(student), "更新失败");
}
public void deleteById(Long id) {
Assert.isTrue(studentManager.removeById(id), "删除失败");
}
服务层方法是指某个领域对外提供的业务功能,以 学生信息 这个领域为例,它提供了 获取列表 、 获取详情 、 新增 、 更新 、 删除 功能服务。
正如我在我的 Java 规范中讲到,在服务层中的命名应该优先以服务名称命名,而不是以数据逻辑变化命名。
正例: disableById(Long id) 、 enableById(Long id)
反例: updateStatusBy(Long id,Integer status)
对于领域的业务来说,我们是要将领域对象禁用或启用,虽然这两个操作本质上就是修改属性状态,但如果直接把修改状态(命名)的方法写在服务层,就把服务层和 DAO 层的边界模糊了,对于调用服务层方法的人来讲,他只需关心我要的服务是什么,而不需要知道服务实现的逻辑是什么,也就是在上例中,调用者不需要知道是通过修改 status 属性来表示禁用或启用的。
在阅读「设计模式之美」一书后,我在自己的项目中,不再使用 接口 + 实现类 的方式来编写 Service 层,Service 层绝大多数时候都是单实现的,单实现就没有必要声明接口了,函数本身就具备抽象的概念,只使用实现类即可。
# 数据仓库层 Repository
- 对第三方平台封装的层,预处理返回结果及转化异常信息,适配上层接口。
- 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理。
- 与 DAO 层交互,对多个 DAO 的组合复用。
@Repository
public class StudentRepositoryImpl implements StudentRepository {
@Override
public List<Student> list(StudentQuery query) {
Student student = BeanUtil.copyProperties(query, Student.class);
return this.list(Wrappers.query(student));
}
}
本层与下面的数据访问层,都属于 Model 层的细分,这一层不是一定存在的,很多项目中把它和服务层耦合在一起,而为什么我们需要把它拆分出来呢?
在使用 MyBatis 做 DAO 时,大部分时候我们都是 Service 直接依赖 Mapper,而在企业开发中,为提高开发效率,会使用类似 MyBatis-plus(下面简称 mp)的增强 ORM 框架,而对于简单的单表 CURD,mp 提供了一个 条件构造器 的功能,这功能可在 Java 代码中实现对数据库的简单操作
MyBatis与MyBatis-Plus对比
原生 MyBatis 写法:
- 在 Mapper.class 声明接口
- 在 Mapper.xml 编写 SQL
Student student = studentMapper.selectOneByCodeAndName("123","NipGeihou");
MyBatis-Plus 写法:
- 在
Service 层(很多人)编写
Student student = lambdaQuery()
.eq(Student::getCode, "123")
.eq(Student::getName, "NipGeihou")
.one();
如果把 mp 的 lambda 查询构造器写在 Service 层,就会把 mp 与 Service 层耦合在一起,如果之后更改了 ORM 框架,不再使用 MyBatis (-Plus) 那么对于代码的改动将会影响到 Service 层。
此外当我们需要缓存数据时,我们将需要这样一段伪代码
Student student = CacheUtil.get("123", Student.class);
if (Objects.isNull(student)) {
student = baseMapper.selectById(1L);
CacheUtil.set("123", student);
}
我们为了 少写SQL 、 优化性能 等因素,把一堆与服务逻辑不相干的代码拼凑在服务层中,因此我们将这一些与数据持久化相关的代码抽取到此层,从而使服务层无需关心如何处理缓存一致性、持久化方案,只需知道调用了此层必然能新增、修改、删除、查询领域数据即可。
# 数据访问层 DAO、Mapper
数据访问层,与底层 MySQL、Oracle、Hbase、OceanBase 等进行数据交互。
这一层没有特别多可以讲的,需要主要的一点是,在入参和出参时应使用 entity 或其属性作为参数,而不应使用 entity 属性子集 DTO 作为入参出参,除非 entity 不能满足需求时,如联表查询。
示例代码:https://github.com/NipGeihou/code-example (opens new window)
# 层对象传递
# 分层领域模型规约
在探讨层与层之间的对象如何传递之前,首先我们需要对一些术语有一定了解。
分层领域模型规约:
DO(Data Object):此对象与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
DTO(Data Transfer Object):数据传输对象,Service 或 Manager 向外传输的对象。
BO(Business Object):业务对象,可以由 Service 层输出的封装业务逻辑的对象。
Query:数据查询对象,各层接收上层的查询请求。注意超过 2 个参数的查询封装,禁止使用 Map 类来传输。
VO(View Object):显示层对象,通常是 Web 向模板渲染引擎层传输的对象。
在本文中我们只探讨 DTO 和 DO,我们不必纠结对象的后缀到底该怎么命名,我们需要知道的是这些对象应该用在哪里,对象与对象如何转换?
# 为什么需要 DTO
在一些小项目中,领域模型通常只有一个他放在 pojo 、 domain 、 entity 、 do 等包下,以 Student.class 为例,他贯穿控制器、服务层、DAO 层,而在看一些规范文档中他们会将模型细分为 DO 、 DTO 、 BO 、 Query 等,为什么需要细分呢?
举个例子:HTTP参数污染
过程
用户张三的账号因为某些原因被系统限制,而限制的系统逻辑则是把 user 表的 status 字段改为 9(正常为 1),而张三发现系统有一个修改用户信息的页面,可以修改用户头像、名称、手机号等基本信息,张三抓取请求信息后,使用 Postman 在请求体中添加了 "status":1 发送,成功把账号从受限状态变成正常状态。
原因
查看代码发现,控制器方法入参写的 update(User user) ,而之后的服务层、DAO 层都没有对入参进行校验,全靠前端校验,而对于另辟蹊径的人就可以绕过前端校验了。
解决
那可以怎么解决呢?
方法一:在服务层把实际允许更新的字段一个个 set 到另一个对象中,而这样的缺点也很明显,如果可以更新的字段越多,服务层中 set 的代码越多。并且如果之后对字段有调整,还需要侵入 service 代码修改。
方法二:使用 DTO 入参,DTO 通常是 Entity (DO) 的子集,在 DTO 中只定义了允许修改的字段,因此不管前端怎么传参,后端控制器也只接收 DTO 中的属性,在控制器 @Validated 做参数校验后,再将 DTO 传递到服务层。
# 关于 DTO
DTO 数据传输对象它应该是一种设计模式,而不是一种命名规范,因此在实际项目中,除了以 DTO 作为后缀,也有使用 XxxxReq 、 XxxxParam 作为后缀的,DTO 是对出入参的明确,而不是用 Entity 对象一把梭。
public List<StudentResp> list(StudentQuery query)
public void save(StudentReq req)
public void updateById(StudentReq req)
在上文的示例中, StudentQuery 、 StudentReq 都是 DTO,如果进一步细分,应该 save 的 DTO 是 StudentCreateReq , updateById 的 DTO 是 StudentUpdateReq ,虽然在前端交互中,很多时候新增页面和编辑页面是复用的,但两者的入参是有不同的,比如说新增不接收 id ,编辑必须有 id ,如果有类似单号等新增后不允许修改的字段,那么新增和修改的 DTO 就有明显区别了,因此必要时应该分离新增和修改 DTO。
# DTO 的作用域
我们已经知道为什么要在控制器入参使用 DTO,那么是不是我们应该把 DTO 贯穿控制器层、服务层、通用业务处理层、数据访问层?
我的答案:不是,我们要明确之所以有 DTO,是因为业务需要我们要明确服务层调用者的入参,而并不是持久化层只能存这些对象数据,持久层面向的是 Entity,他的职责就是对 Entity 对象的增删改查,因此在调用持久化层前,应将 DTO 转化为 Entity 对象操作,也不应把业务逻辑带到持久化层,从而模糊了 Service 层与持久化层的边界。
# 结语
在本文中,我尝试探讨了当下 MVC 分层与层对象传递的最佳实践,随着开发经验增加,我会不时修正本文中的一些观点。
# 参考资料
- Gunther Popp. To DTO or not to DTO ...[EB/OL]. [2022-8-17]. http://guntherpopp.blogspot.com/2010/09/to-dto-or-not-to-dto.html (opens new window).
- alibaba. Java 开发手册 [EB/OL]. [2022-8-17]. https://github.com/alibaba/p3c (opens new window).
- Andreas. How to use DTOs in the Controller, Service and Repository pattern[EB/OL]. [2022-8-17]. https://stackoverflow.com/questions/61303236/how-to-use-dtos-in-the-controller-service-and-repository-pattern (opens new window).
- 极客时间。你的项目应该如何正确分层?[EB/OL]. [2022-8-18]. https://zhuanlan.zhihu.com/p/150463059 (opens new window).