 Hadoop HDFS
Hadoop HDFS
本文以 Hadoop 3.x 为例
# 为什么需要分布式存储
- 单机存储受限:文件太大,单机装不下
- 读写性能提升:随着使用分布式存储,可以并发读写,随之就是读写性能的提升。
# 分布式的基础架构分析
使用分布式时,就需要面临调度问题,怎么存?存哪里?怎么读?从哪读?
- 去中心化模式:没有明确中心,大家协调工作
- 中心化模式:有明确的中心,基于中心节点分配工作
# 主从模式 (Master And Slaves)
中心化架构,Hadoop 就是一个典型的主从模式架构的技术框架
# HDFS 的基础架构
HDFS 全称:Hadoop Distributed File System
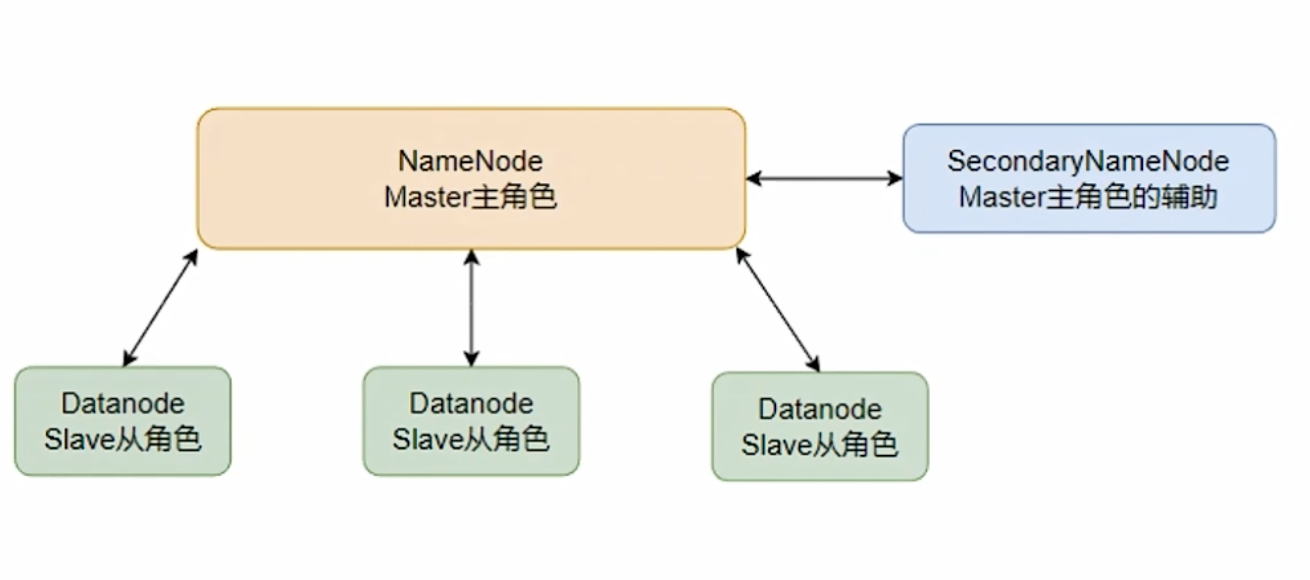
# NameNode
- HDFS 系统的主角色,是一个独立的进程
- 负责管理 HDFS 整个文件系统
- 负责管理 DataNode
# SecondaryNameNode
- NameNode 的辅助,是一个独立进程
- 主要帮助 NameNode 完成元数据整理工作(打杂)
# DataNode
- HDFS 系统的从角色,是一个独立进程
- 主要负责数据的存储,即存入数据和取出数据
# HDFS 集群环境部署
# 准备服务器
| 节点 | CPU | 内存 | 硬盘 | IP | 服务 |
|---|---|---|---|---|---|
| node1 | 1 | 4GB | 20g | 192.168.1.101 | NameNode、DataNode、SecondaryNameNode |
| node2 | 1 | 2GB | 20g | 192.168.1.102 | DataNode |
| node3 | 1 | 2GB | 20g | 192.168.1.103 | DataNode |
Note
上述为原教程配置,本文统一使用 2C/8G/20G Ubuntu 22.04 规格实验
# 服务器基本设置
# 设置主机名,这里我在初始化时已经设置,此处略过
# hostnamectl set-hostname node1
# 修改固定IP地址,这里我在初始化时已经设置,此处略过
# 配置hosts(windows也要)
vim /etc/hosts
192.168.1.101 hadoop-node1
192.168.1.102 hadoop-node2
192.168.1.103 hadoop-node3
# 设置(root)免密登陆
ssh-keygen -t rsa -b 4096 # 生成密钥对
ssh-copy-id node1 # 复制本机当前用户公钥到node1
ssh-copy-id node2 # 复制本机当前用户公钥到node2
ssh-copy-id node3 # 复制本机当前用户公钥到node3
# 测试免密登陆
ssh node1
ssh node2
ssh node3
# 创建用户hadoop
useradd hadoop
passwd hadoop # 设置hadoop用户密码
su - hadoop # 切换hadoop用户
ssh-keygen -t rsa -b 4096 # 生成密钥对
ssh-copy-id node1 # 复制本机当前(hadoop)用户公钥到node1
ssh-copy-id node2 # 复制本机当前(hadoop)用户公钥到node2
ssh-copy-id node3 # 复制本机当前(hadoop)用户公钥到node3
# 下载 Hdoop
- 下载地址:Apache Hadoop (opens new window)
- 下载最新版的二进制 (binary) 安装包
# HDFS 的存储原理
# HDFS 的 Shell 操作
上次更新: 2024/10/24, 01:30:13