 查找
查找
# 基本概念
查找长度:在查找运算中,需要对比关键字的次数称为查找长度
平均查找长度(ASL,Average Search Length):所有查找过程中进行关键字的比较次数的平均值
# 顺序查找
顺序查找,又称为 “线性查找”,通常用于线性表。 即从头找到脚
时间复杂度:
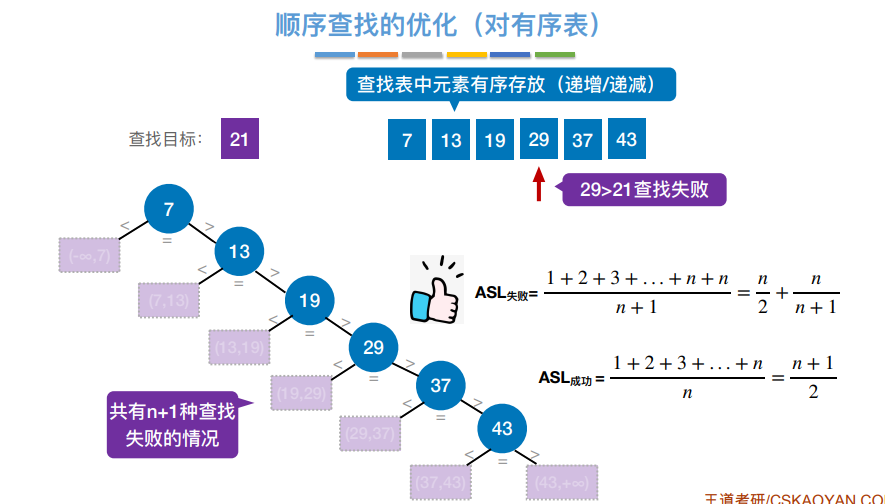
优化
- 将元素排序,可降低失败 ASL
- 将被查找概率高的元素靠前,可降低成功 ASL
二者不可兼得,不管如何复杂度都是
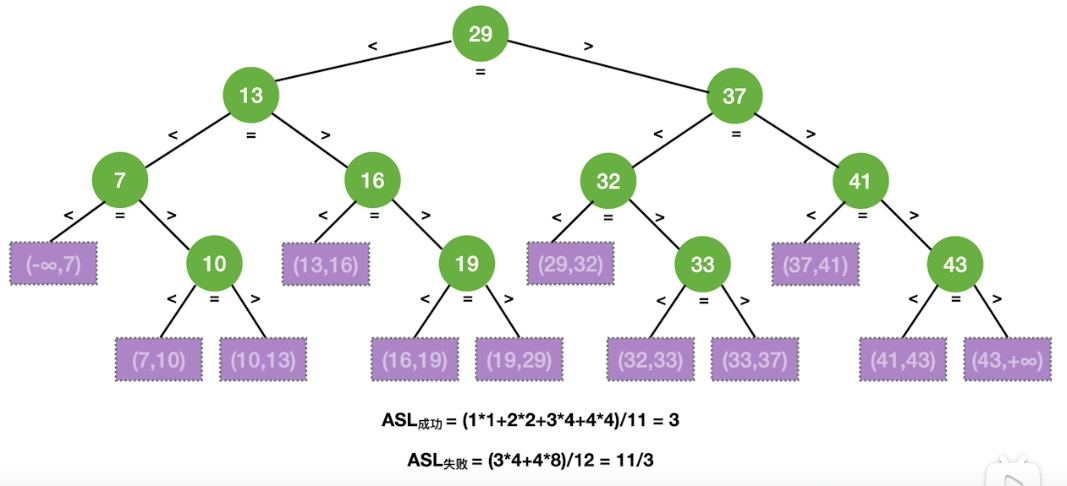
# 折半查找(二分查找树,BST)
折半查找,又称 “二分查找”,仅适用于有序的顺序表。
时间复杂度:
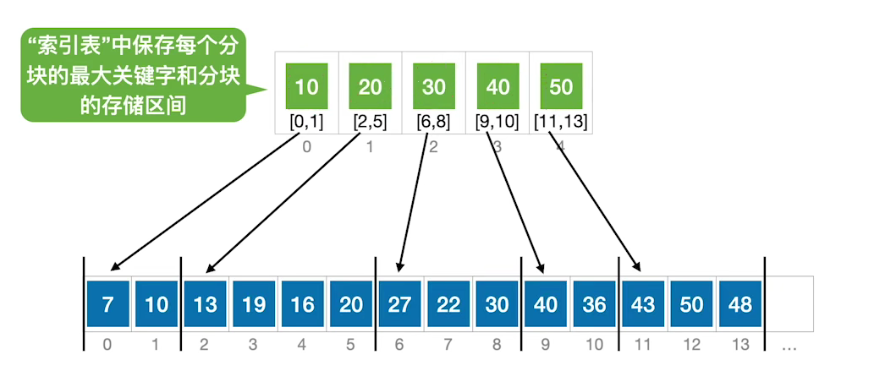
# 分块查找
特点:块内无序,块间有序
分块查找,又称索引顺序查找,算法过程如下:
- 在索引表中确定待查记录所属的分块(可顺序、可折半)
- 折半查找:若索引表中不包含目标关键字,则折半查找索引表最终停在 low>high,要在 low 所指的分块中查找。
- 在块内顺序查找
# 查询效率分析
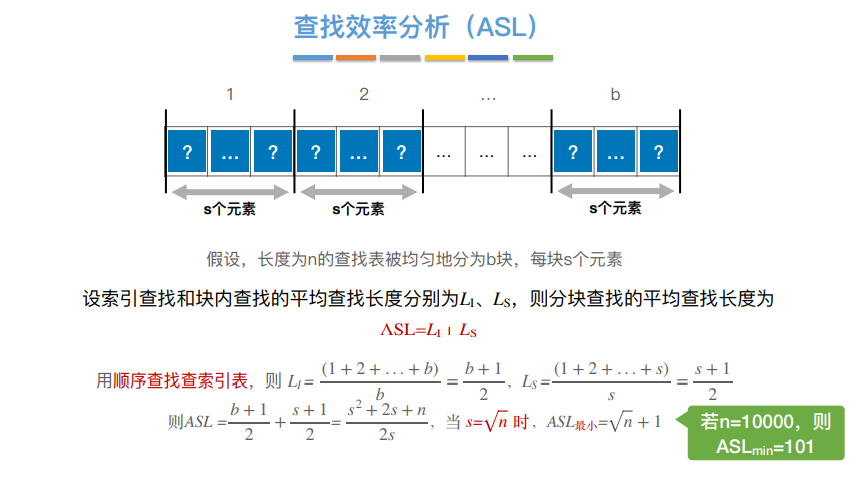

# m 叉查找树
为什么要有m叉查找树
随着关键字的增加,二分查找树的高度逐渐增高,性能降低,而 m 叉查找树可以改善性能,当然这就跟二叉树一样,如果没有限制,那么它会退化成链表,m 叉查找树如果没有限制,也会退化成链表、二叉树,所以学习 m 叉查找树,只是为了引出下面的 B 树。
# 概念
- 失败结点:即为 null
- 最少 1 个关键字,2 个分叉;最多 m-1 个关键字,m 个分叉
- 结点内关键字有序
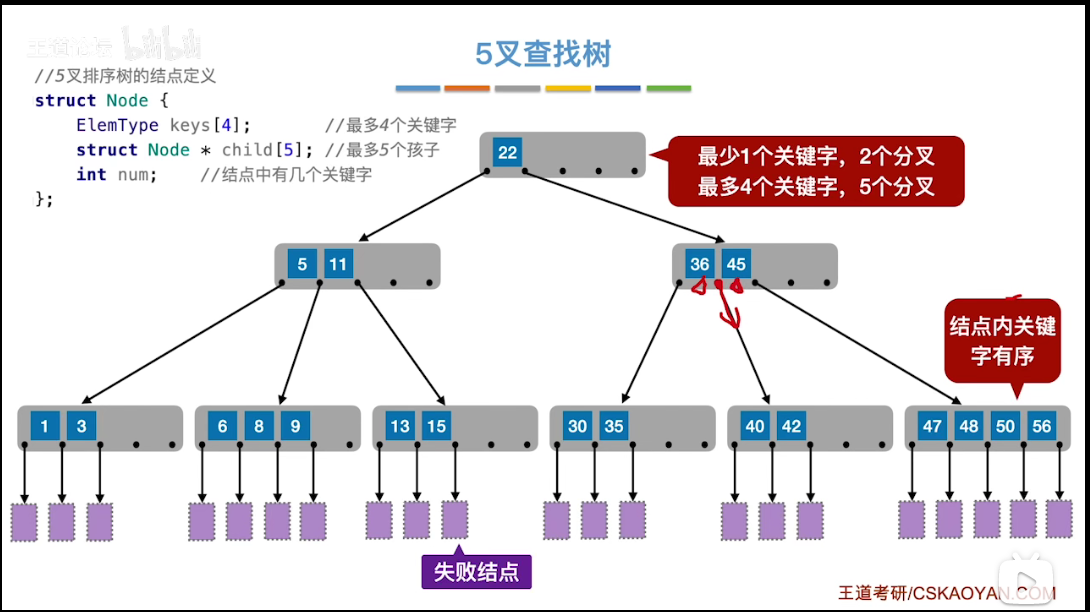
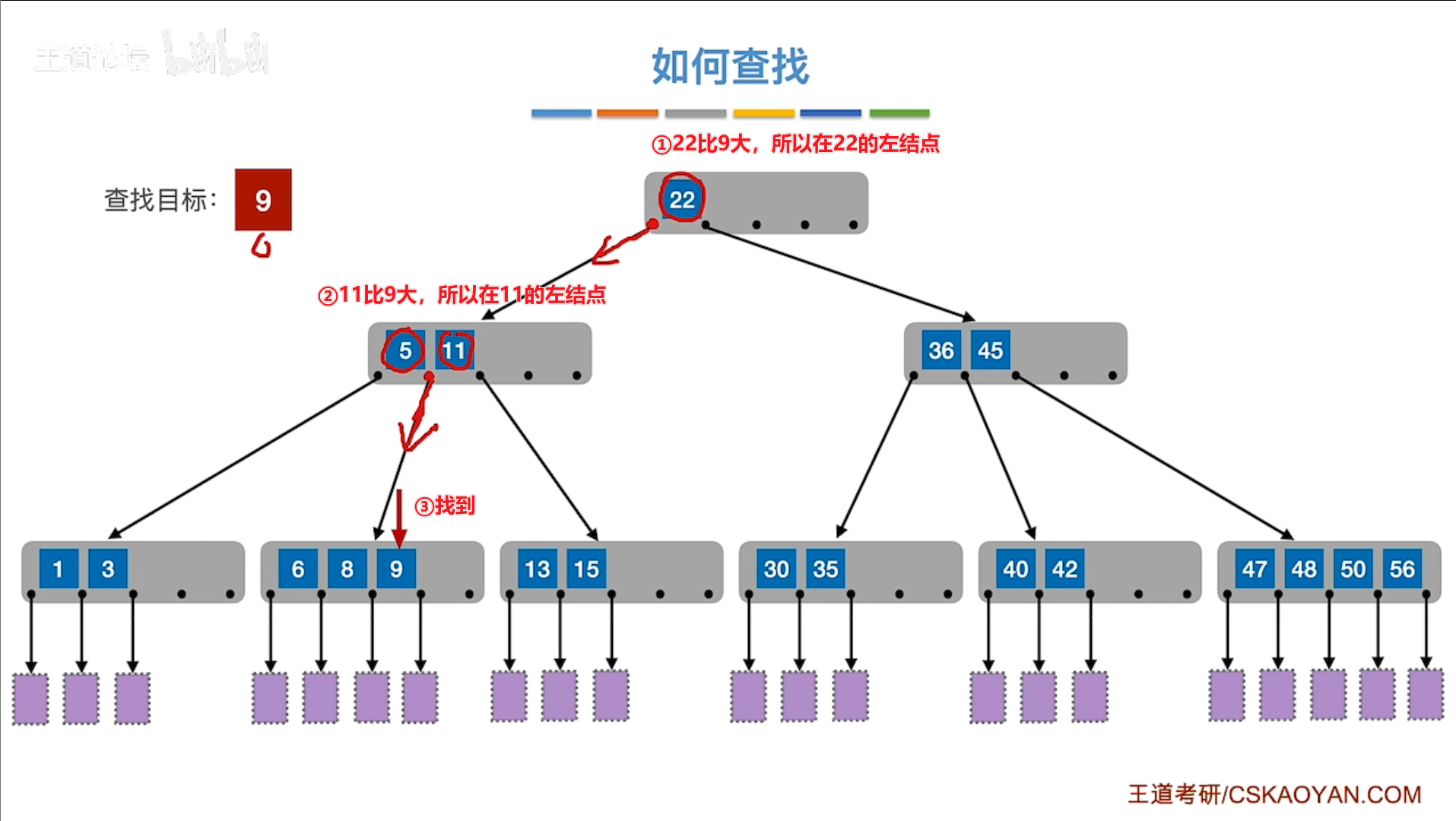
# 查找
- 由于结点内关键字数组是有序的,因此可以使用折半查找提高效率。
# 查找成功
# 查找失败
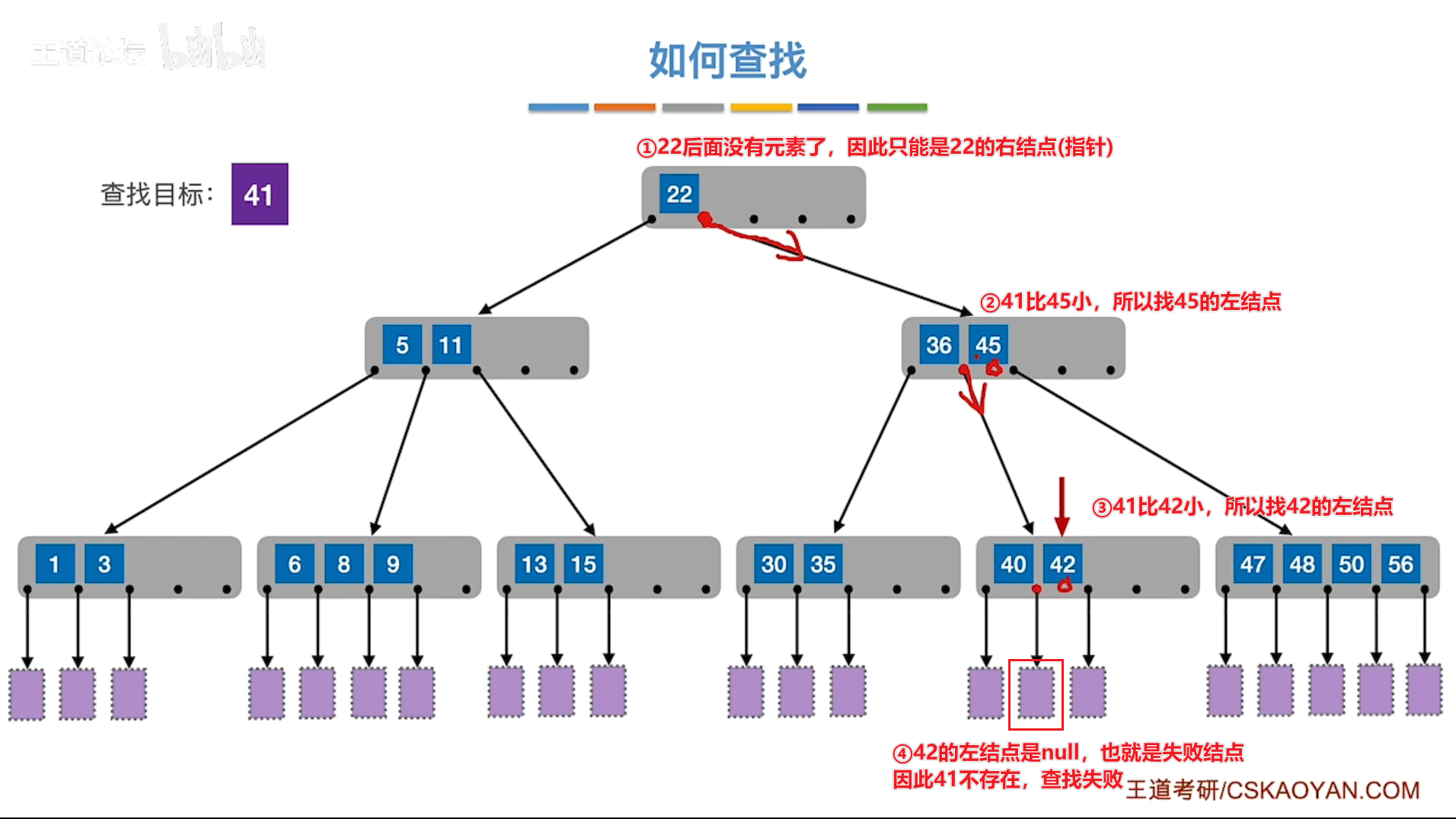
# 缺点
# 结点关键字少
如果每个结点内关键字太少,会导致树变高,甚至退化成二叉查找树,即需要查询更多层结点,效率低。
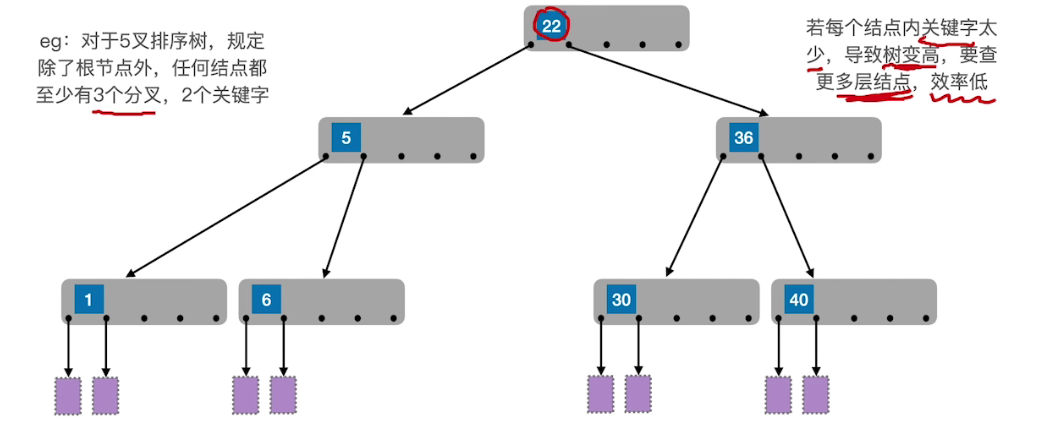
# 不平衡
不够平衡,树高度,效率低
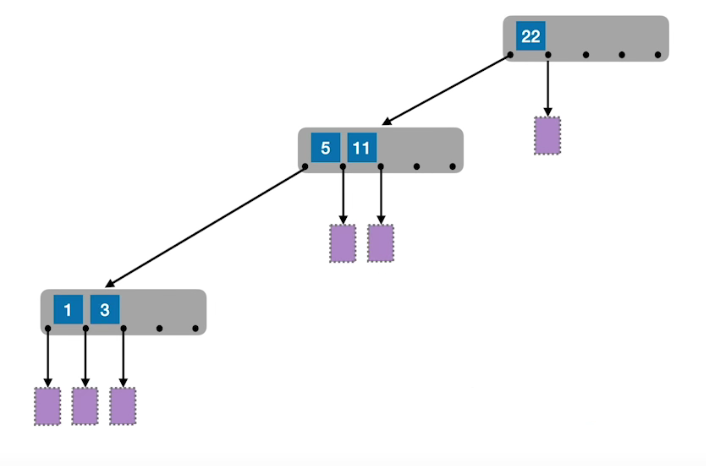
因此需要一些规则去解决上述问题,而添加规则之后,便是下面的 B 树。
# B 树
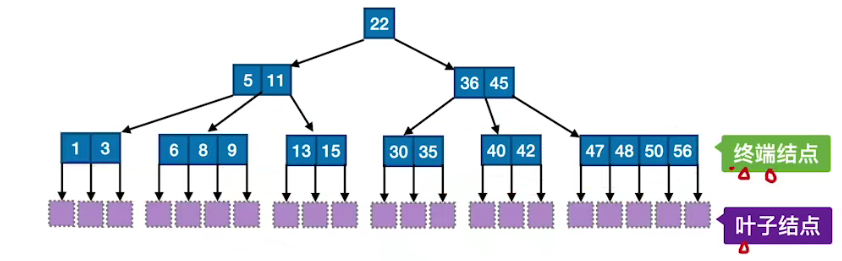
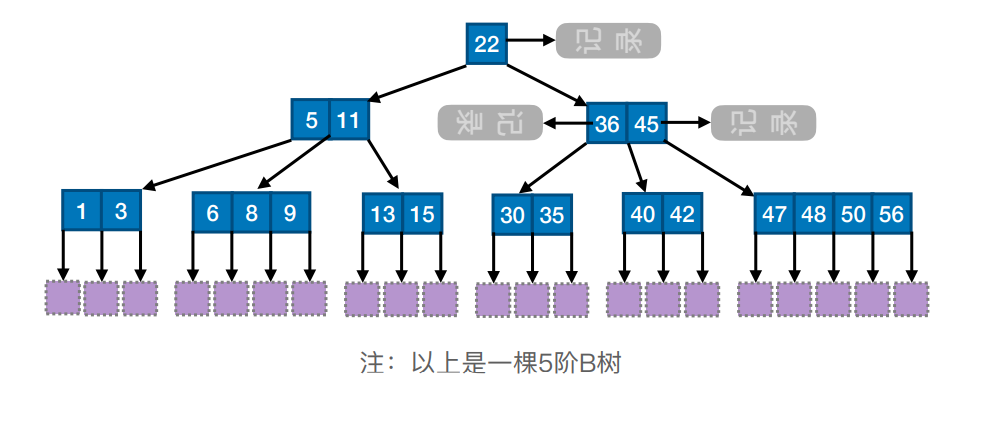
B 树的结点中都含有了关键字对应的记录的存储地址
# 概念
B 树,又称多路平衡查找树。
B 树的阶:B 树中所有结点的孩子个数的最大值称为,通常用
注:大部分学校算 B 树的高度不包括叶子结点(失败结点)
最小高度:让每个结点尽可能满,有 m-1 个关键字,m 个分叉,因此
最大高度:让每个结点包含的关键字、分叉尽可能的少。记
若关键字总数少于这个值,则高度一定小于
满足如下特征的 m 叉树即为 B 树:
- 树中每个结点至多有
个分叉 (子树),即至多含有 个关键字。 - 若根结点不是终端结点,则至少有两个分叉 (子树)。
- 除根节点外,所有非叶结点至少有
个分叉 (子树),即至少含有 个关键字。—— 核心特征 - 对于任何一个结点,其所有子树的高度都要相同。—— 核心特征
- 所有的叶结点都出现在同一层次上,并且不带信息(指针为 NULL)。
B树与m叉查找树的区别
B 树的两个核心特征,也是 m 叉查找树与 B 树的区别所在,m 叉树的性质之上添加了两个核心特征便是 B 树。
# 查找
与 m 叉查询树 - 查询相同
# 插入
新元素一定是插入到最底层 “终端结点”,用 “查找” 来确定插入位置
情况一,终端结点放得下:直接当有序数组插入

情况二,终端结点放不下:从中间位置 (
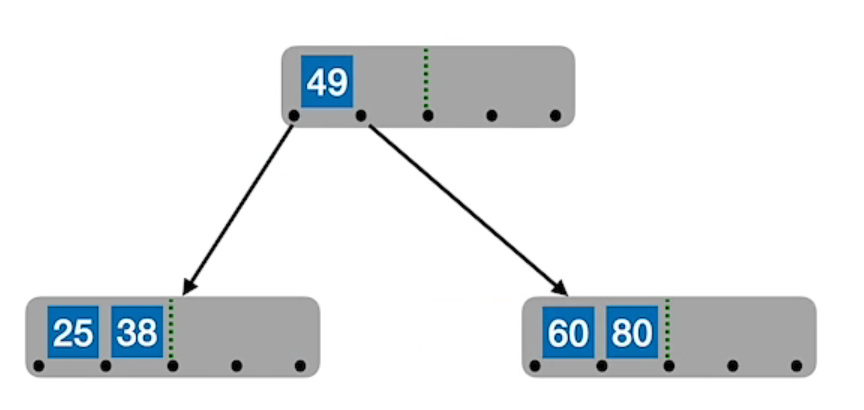
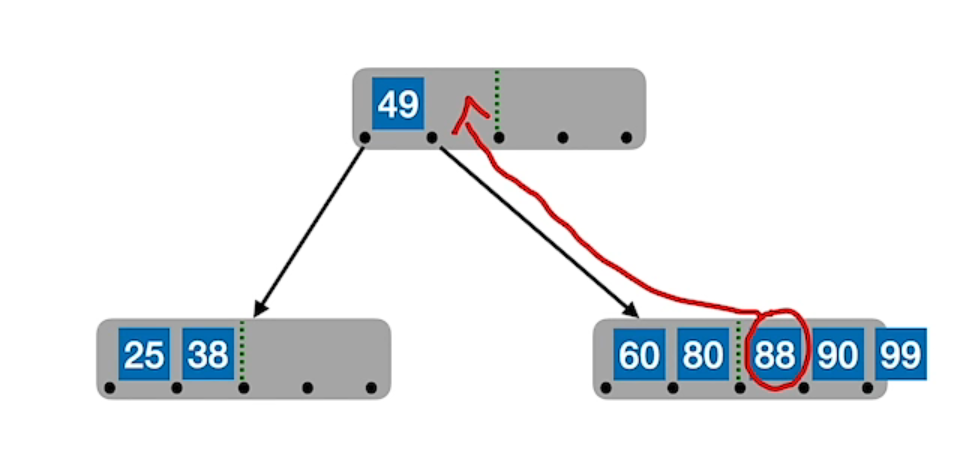
在插入 key 后,若导致原结点关键字树超过上线,则从中间位置(
# 缺点
# 不支持顺序查找
B 树仅适合用于寻找某一条数据的场景,当需要根据关键字排序的多条记录时,比如按创建时间 (关键字) 倒序查找 10 条记录,B 树的数据结构无法满足此场景。
# B + 树
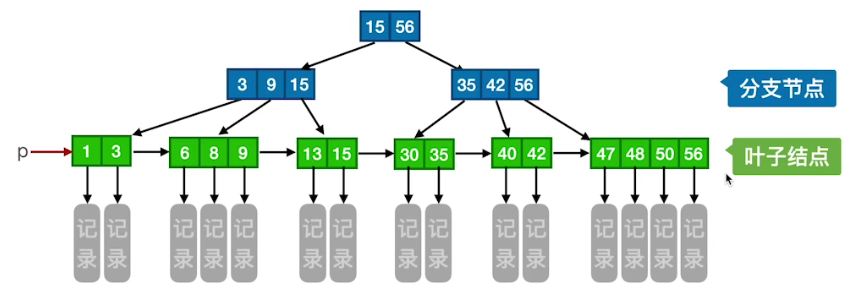
# 概念
一颗 m 阶的 B + 树需满足下列条件:
- 每个分支结点最多有 m 棵子树(孩子结点)
- 非叶根节点至少有两颗子树,其他每个分支结点至少有
棵子树。 - 结点的子树 (分叉) 个数与关键字个数相等。
- 所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序相互链接起来【支持顺序查找】。
- 所有分支结点中仅包含它的各个子结点中关键字的最大值及指向其子结点的指针。
# 查找
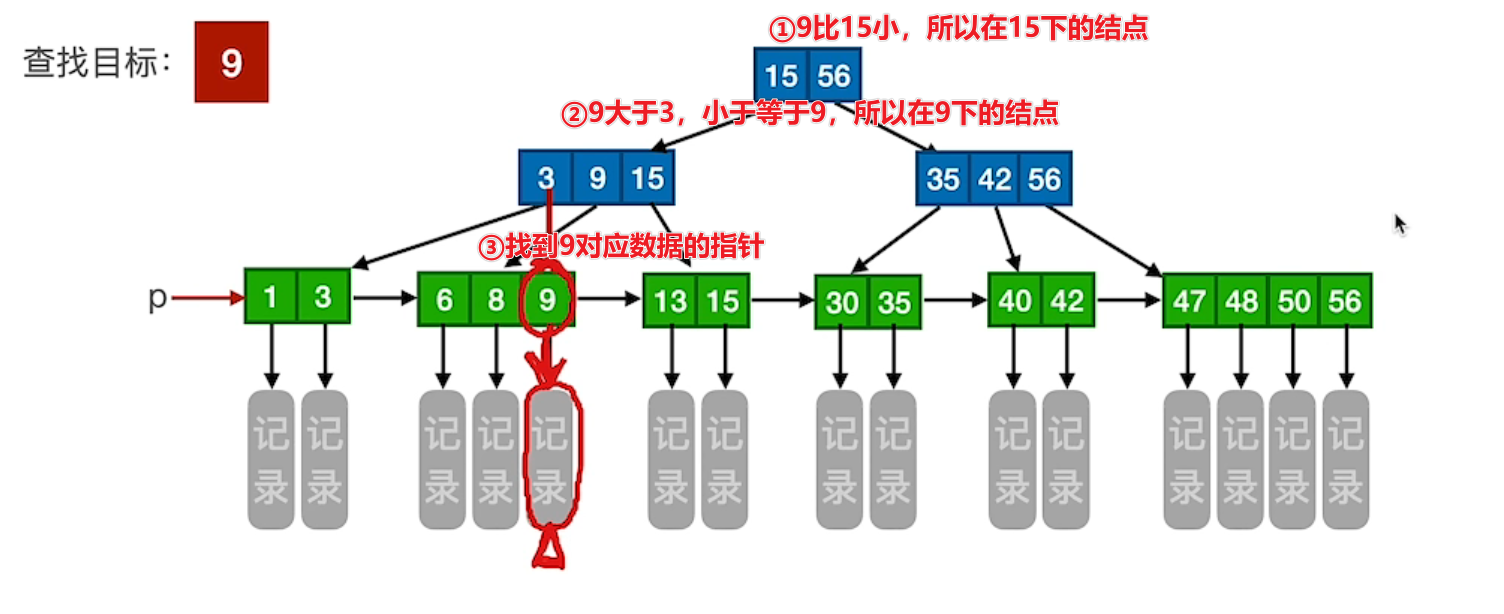
# 查找成功
# 查找失败
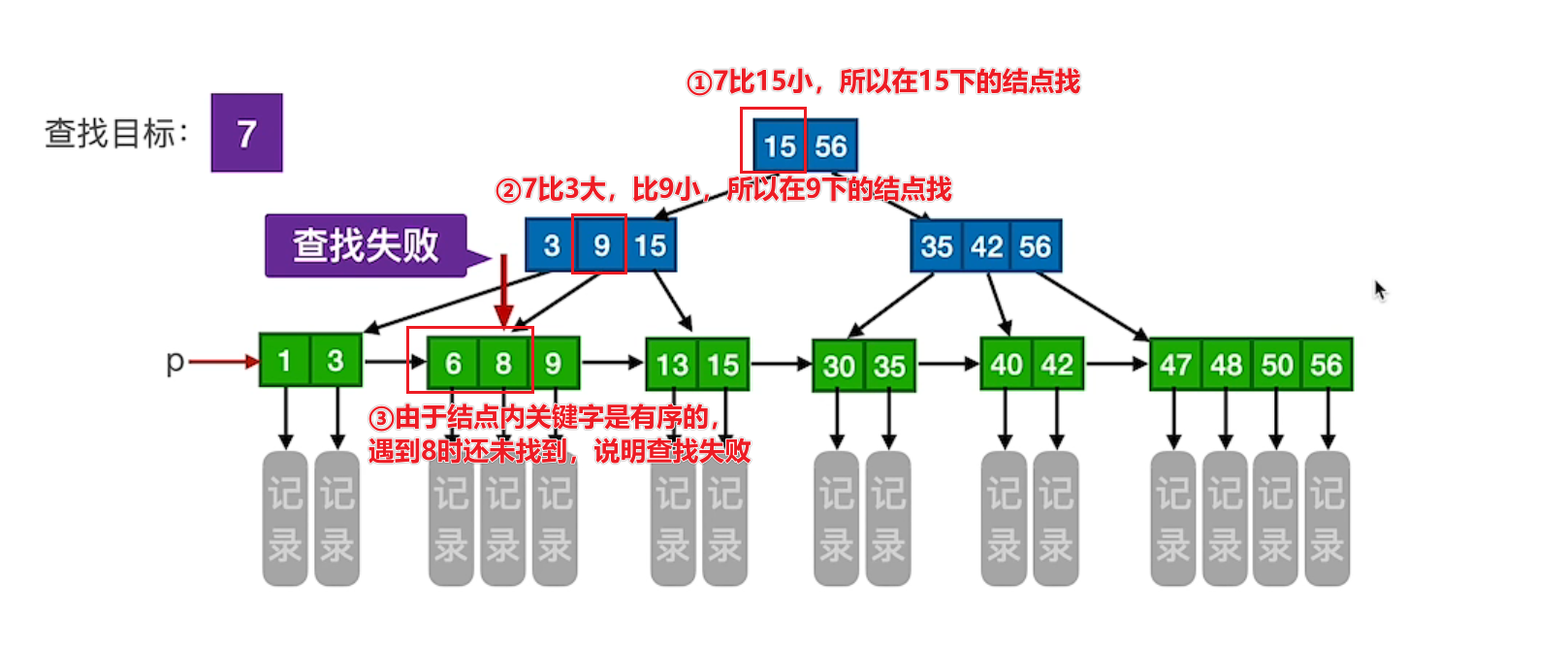
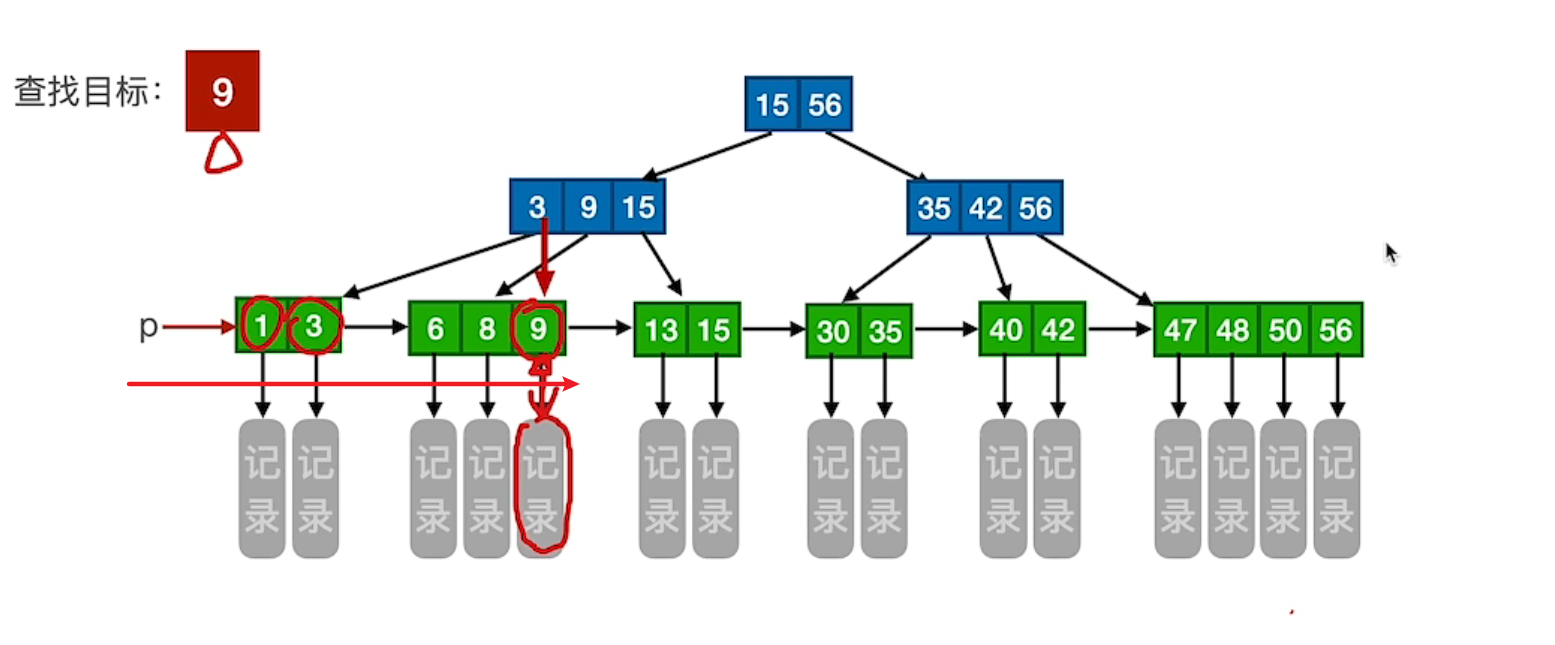
# 顺序查找
通过 p 指针顺序查找
# B 树与 B + 树的区别
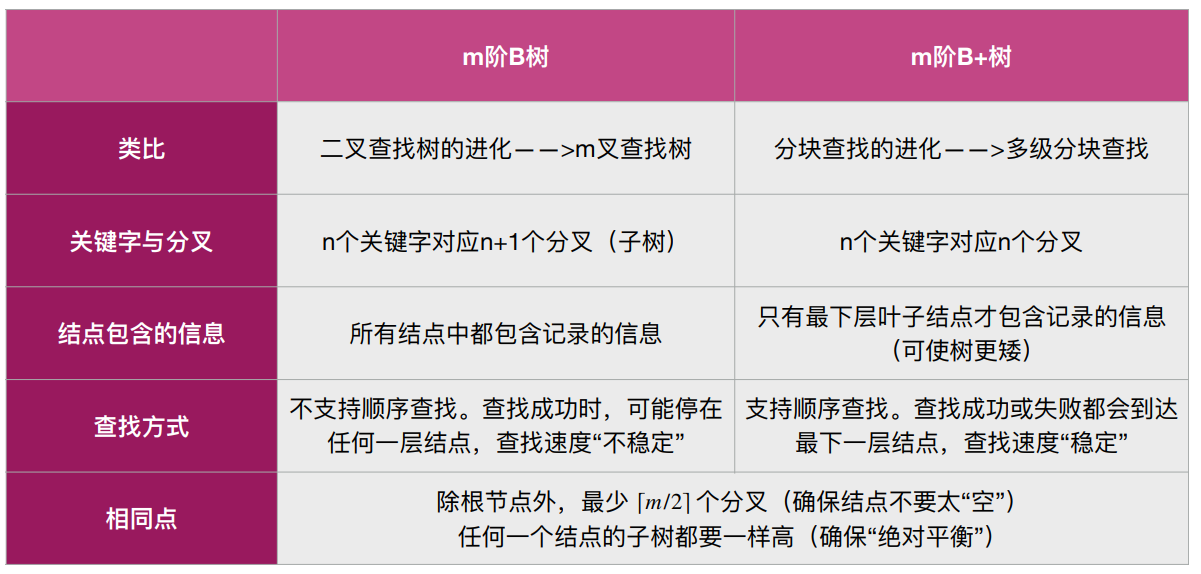
在 B + 树中,非叶结点不含有该关键字对应记录的存储地址。可以使一个磁盘块可以包含更多个关键字,使得 B + 树的阶更大,树高更矮,读磁盘 (IO) 次数更少,查找更快。
为什么要追求树更矮?
在实际场景中,查询记录最耗时的是 IO,即加载磁盘找那个的数据到内存中。以上图中的 B + 树查找 42 为例:
- 系统将根结点(通常为一个磁盘块大小)从磁盘读取到内存中,判断得,可能在 56 关键字结点下
- 读取 56 关键字结点,判断得,(可能) 在 42 关键字结点下
- 读取 42 关键字结点,找到 42 关键字记录指针
- 读取 42 关键字记录指针
在上述过程中,每一次 读取 都需要在磁盘上寻找,由于传统机械硬盘 (HHD) 是物理寻找的,因此相对耗时,而更矮的树能减少读取次数,提高查询效率。
值得一提的是,在使用固态硬盘 (SSD) 作为外存时,得益于固态硬盘优秀的随机读取能力,更矮的树带来的查询效率提示变得不再明显。但这并不代表 B + 树已经过时,它依然是一种优秀的数据结构,也因为固态硬盘的数据安全性问题,也很少有在生产场景中使用。
笔记
B + 树,作为 MySQL 默认的数据结构,几乎每天都在和它打交道,B + 树难道就是最优解吗?它更多的是机械硬盘下的最优解,当使用固态硬盘或者内存作为 “存储介质” 时,Java 中使用的红黑树、Redis 中使用的跳表也能够从容应对。
# 红黑树(Red Black Tree,RBK)
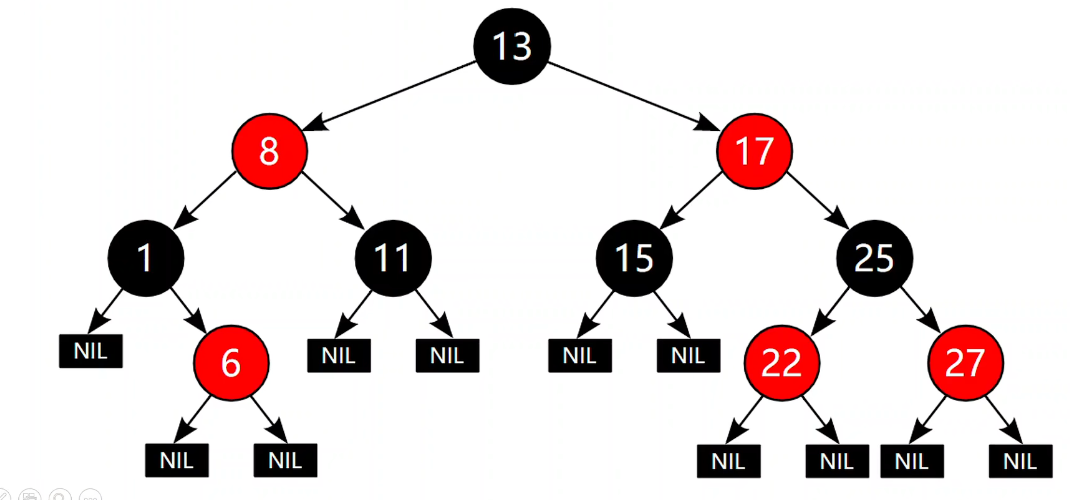
AVL平衡二叉树存在的问题
由于 AVL 对 “平衡” 的要求太高,几乎每次插入都需要进行调整,使得插入的性能降低,而红黑树则是在查询与插入效率平衡的结果,即防止二叉树退化成链表,又减少结点调整次数。
概念
红黑树,排序二叉树的一种变种。
- 根节点是黑结点
- 叶子结点 (null) 是黑结点;(可知一半以上都是黑结点)
- 红结点的子结点必须是黑结点
- 新插入的结点是红结点
- 任意结点到叶子结点路径中的黑结点相同
最坏情况:左右子树高度差为一倍,如左子树全是黑结点,右子树黑红相间的结点。
最高高度:
# 查询
与排序二叉树查找一样
# 插入
# 空树
插入插红结点
转为黑结点

# 父结点是黑结点
- 插入红结点
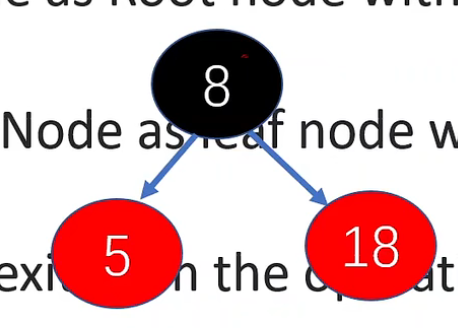
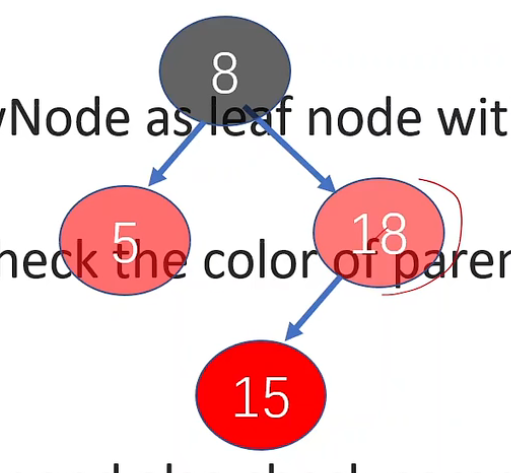
# 父结点是红结点,父 - 兄为红结点
- 插入红结点
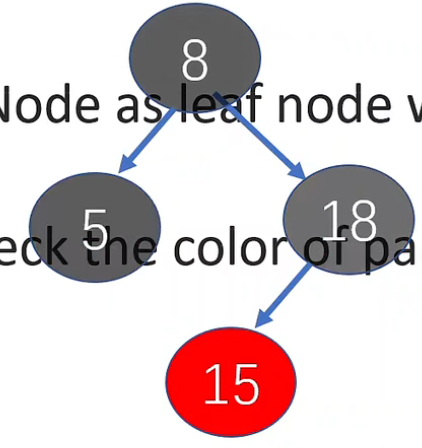
- 把父结点 (5)、父结点的兄弟结点 (18) 转为黑结点
- 判断父 - 父结点是否是根节点,是时结束
# AVL 树与红黑树的区别
- AVL 树:查询效率高,插入效率低,适用于查询远大于插入的场景。
- 红黑树:查询效率中等,插入效率中等,适用于查询、插入同样频繁的场景。
# 散列表(哈希表)
散列表(Hash Table),又称哈希表。是一种数据结构,特点是:数据元素的关键字与其存储地址直接相关
# 处理冲突的方法
# 拉链法
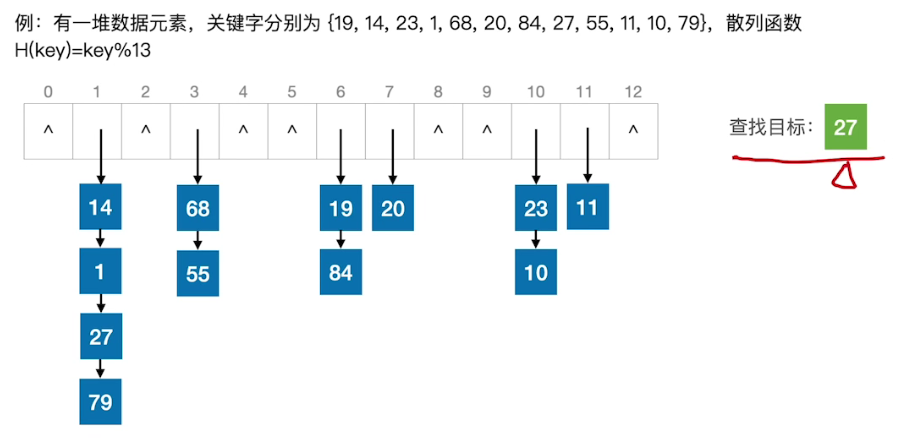
用拉链法(又称链接法、链地址法)处理 “冲突”:把所有 “同义词” 存储在一个链表中
# 开放定址法
开放定址法,是指可存放新表项的空闲地址既向它的同义词表项开放,⼜向它的⾮同义词表项开放。
- 线性探测法 —— 即发⽣冲突时,每次往后探测相邻的下⼀个单元是否为空
- 平⽅探测法 —— 当 di = 02, 12, -12, 22, -22, …, k2, -k2 时,称为平⽅探测法,⼜称⼆次探测法其中 k≤m/2
- 伪随机序列法。di 是⼀个伪随机序列,如 di= 0, 5, 24, 11, …
- 再散列法(再哈希法):除了原始的散列函数 H (key) 之外,多准备⼏个散列函数, 当散列函数冲突时,⽤下⼀个散列函数计算⼀个新地址,直到不冲突为⽌:
注意:采⽤ “开放定址法” 时,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填⼊ 散列表的同义词结点的查找路径,可以做⼀个 “删除标记”,进⾏逻辑删除
# 常见的散列函数
# 除留余数法
散列表表长为 m,取一个不大于 m 但最接近或等于 m 的质数 p
# 直接定址法
其中,a 和 b 是常数。这种方法计算最简单,且不会产生冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费。

# 数字分析法
选取数码分布较为均匀的若干位作为散列地址
设关键字是 r 进制数(如⼗进制数),⽽ r 个数码在各位上出现的频率不⼀定相同,可能在某些位 上分布均匀⼀些,每种数码出现的机会均等;⽽在某些位上分布不均匀,只有某⼏种数码经常出 现,此时可选取数码分布较为均匀的若⼲位作为散列地址。这种⽅法适合于已知的关键字集合, 若更换了关键字,则需要重新构造新的散列函数。

# 平方取中法
取关键字的平⽅值的中间⼏位作为散列地址。 具体取多少位要视实际情况而定。这种方法得到的散列地址与关键字的每位都有关系,因此使得 散列地址分布⽐较均匀,适⽤于关键字的每位取值都不够均匀或均⼩于散列地址所需的位数。
# 跳表(Skip List)
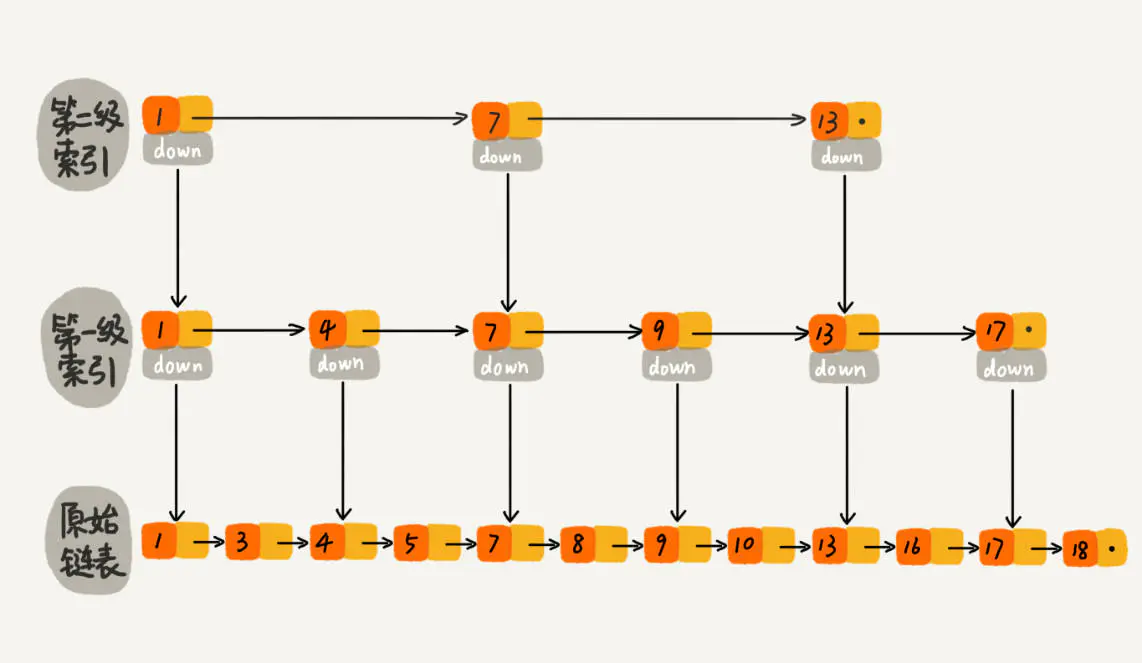
# 概念
有序链表的特点
相较于数组,删除、插入效率高,随机访问效率低
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。
- 用 “空间换时间”,通过给链表建立索引,提高了查找的效率。
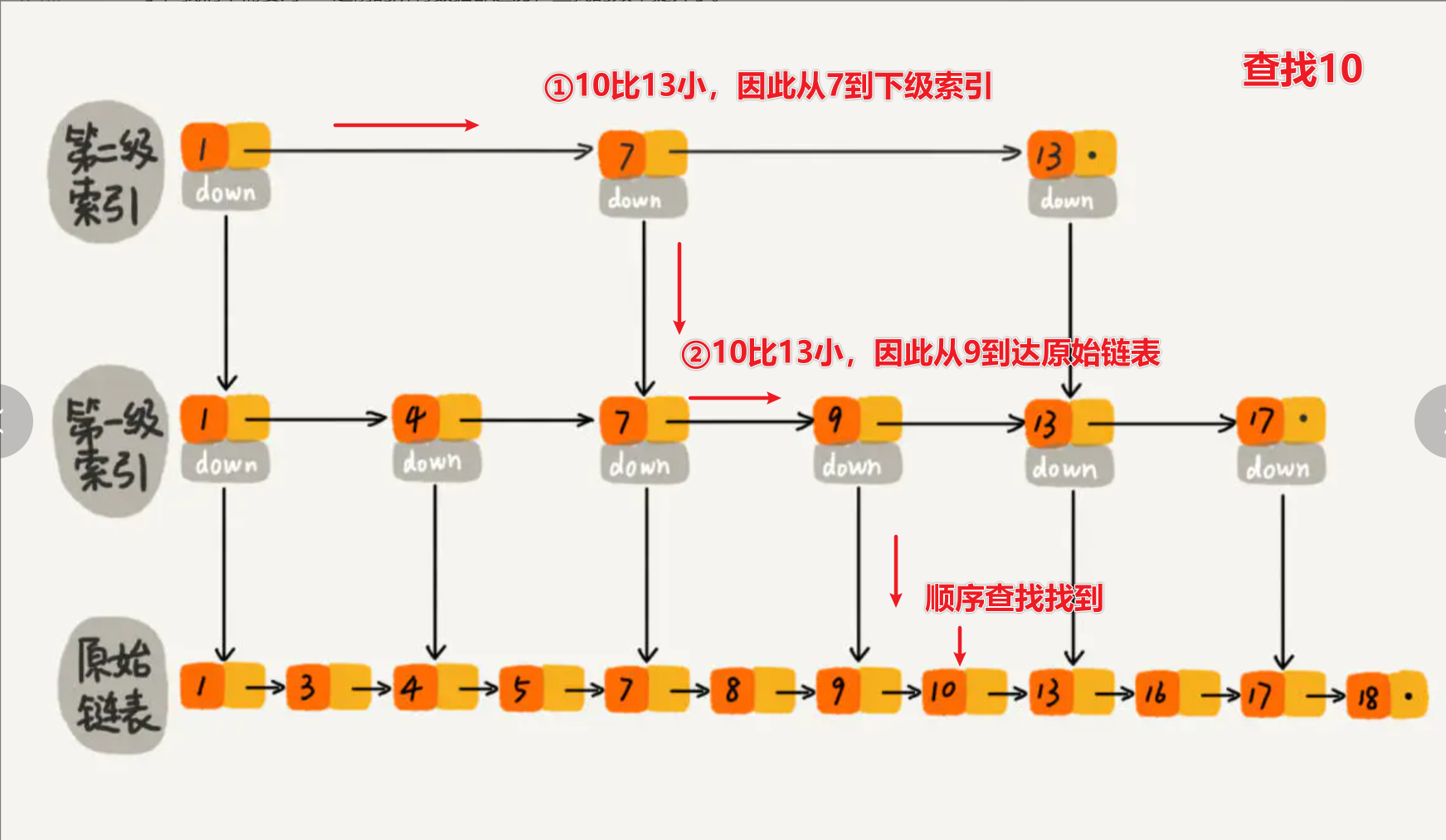
# 查找
# 索引创建
当原始链表中元素数量足够大,且抽取足够随机的话,我们得到的索引是均匀的。
因此只需一个随机算法来确定插入元素时需要创建几级索引即可。
// 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
// 1/2 的概率返回 1
// 1/4 的概率返回 2
// 1/8 的概率返回 3 以此类推
private int randomLevel() {
int level = 1;
// 当 level < MAX_LEVEL,且随机数小于设定的晋升概率时,level + 1
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)
level += 1;
return level;
}
扩展:Redis t_zset.c (opens new window) 中 zslRandomLevel 函数的实现:
点击查看
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
while (random() < threshold)
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
Redis 源码中 (random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF) 在功能上等价于上面代码中的 Math.random() < SKIPLIST_P ,只不过 Redis 作者 antirez (opens new window) 使用位运算来提高浮点数比较的效率。
为什么不重构索引?
重构索引的复杂度为
# 效率分析
# 查找的时间复杂度
- 时间复杂度 = 索引的高度 * 每层索引遍历元素的个数
- 跳表的索引高度
,且每层索引最多遍历 3 个元素。所以跳表中查找一个元素的时间复杂度为 ,省略常数即: 。
# 插入的时间复杂度
# 删除的时间复杂度
# 空间复杂度
假如原始链表包含 n 个元素,则一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2。
# QA
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
Redis 中的有序集合 (zset) 支持的操作:
- 插入一个元素
- 删除一个元素
- 查找一个元素
- 有序输出所有元素
- 按照范围区间查找元素(比如查找值在 [100, 356] 之间的数据)
其中,前四个操作红黑树也可以完成,且时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O (logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。